
Smart redaction for business documents using Python and PassportPDF
Introduction
In this tutorial, you will learn how to perform smart redaction of documents using PassportPDF API and Python. You should have your machine already set up using instructions from the getting started guide.
Why you need document redaction
In many cases, you would want to hide sensitive information from your documents. This information could be personal emails, credit card numbers, or others. Document redaction allows you to remove sensitive and personal data permanently. With PassportPDF Smart Redaction you can automatically find and hide this type of information. You just need to provide the document and the fields you want to redact.
Performing smart redaction on PDF documents
In the following tutorial, we are going to:
- Load a document from a URI using the api/document/DocumentLoadFromURI endpoint.
- Redact the loaded document using the api/documentai/SmartRedaction endpoint.
- Retrieve the redacted document.
- Close the document using the api/document/DocumentClose endpoint.
These steps are shown in the code below:
import requests import base64 if __name__=="__main__": endpoint = "https://passportpdfapi.com/api/document/DocumentLoadFromURI" headers = { "X-PassportPDF-API-Key" : "YOUR-PASSPORT-CODE", } data = { "URI" : "https://passportpdfapi.com/test/invoice_with_barcode.pdf" } response = requests.post(endpoint, json=data, headers=headers) if(response.status_code == 200): json_response = response.json() file_id = json_response["FileId"] data = { "FileId" : file_id, "PageRange" : "*", "Color" : "red", "RedactCreditCardNumbers" : True, "RedactEmailAddresses" : True, "RedactIBANs" : True, "RedactPhoneNumbers" : True, "RedactURIs" : True, "RedactVatIDs" : True, "Immediate" : True } # Redact document redact_endpoint = "https://passportpdfapi.com/api/documentai/SmartRedaction" redact_response = requests.post(redact_endpoint, json=data, headers=headers) if(redact_response.status_code == 200): json_response = redact_response.json() with open("data/output/redacted.pdf", "wb") as file: decoded_data = base64.b64decode(json_response["FileContent"].encode()) file.write(decoded_data) print("Redacted document saved successfully.") else: print("Something went wrong when trying to redact document!") # Close document close_document_endpoint = "https://passportpdfapi.com/api/document/DocumentClose" close_response = requests.post(close_document_endpoint, json={"FileId" : file_id}, headers=headers) if(close_response.status_code == 200): print("Document closed successfully.") else: print("Could not close document!") else: print("Something went wrong!")
When you perform the first step, which is to pass the document as a request to the API, you will get in the response a field called “FileId”. You will then use this field ID to perform document redaction.
You can choose the items you want to redact from your document. Here’s a list of available fields to redact using PassportPDF API:
- Credit card numbers.
- Email addresses.
- IBANs.
- Phone numbers.
- URIs.
- VAT IDs.
Results
The document that we passed to the API looks like this:
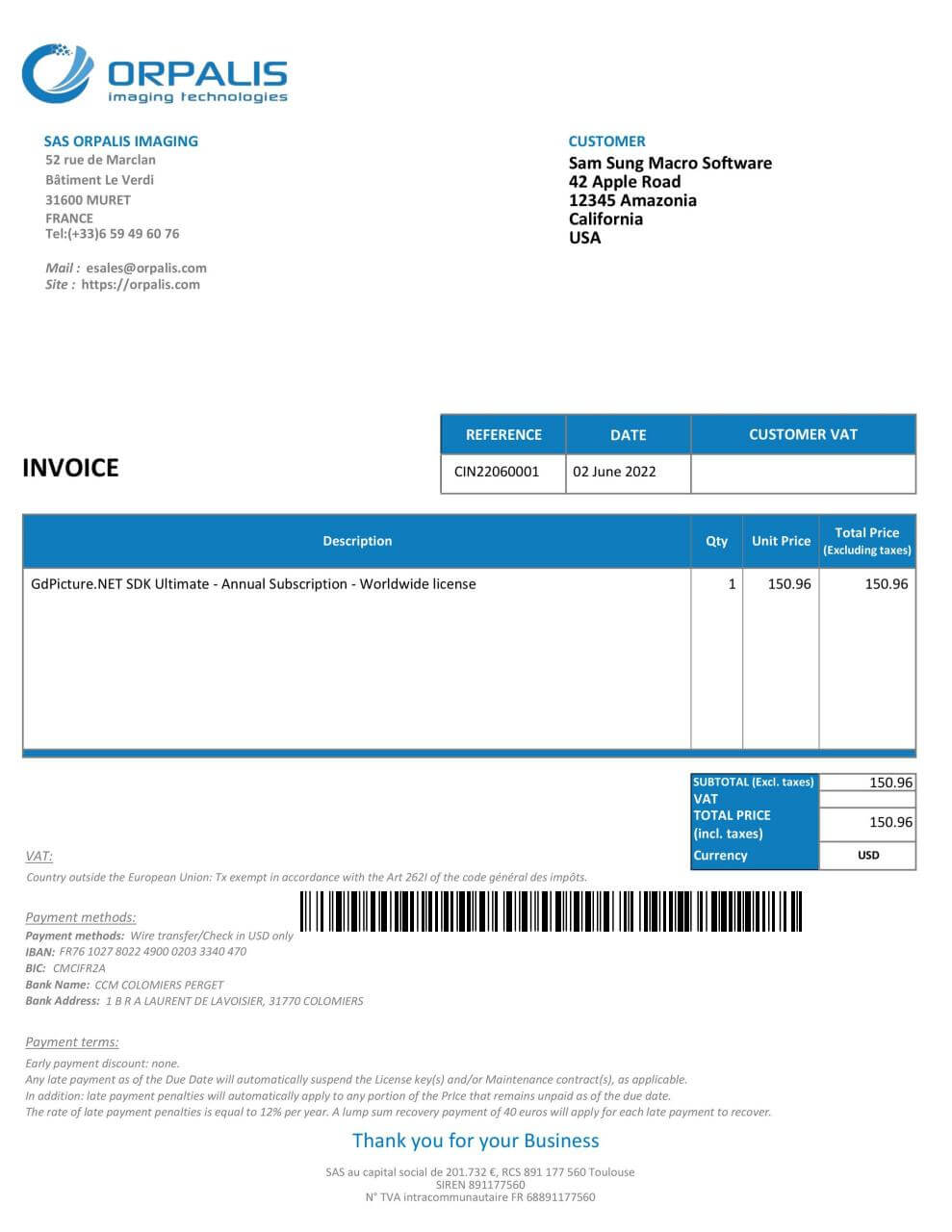
The output of the smart redaction process is below:
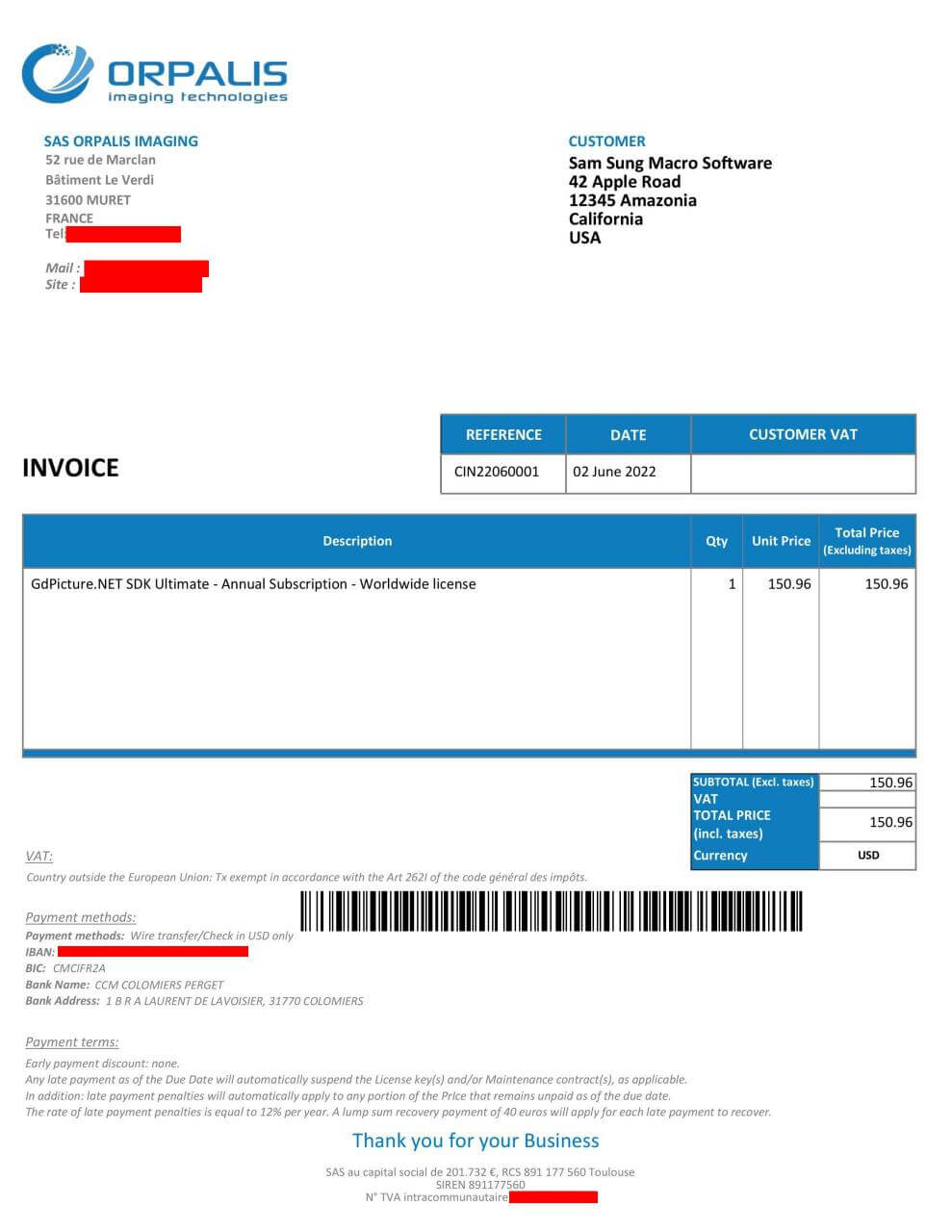
As you can see, all the information that we requested to be redacted has been hidden using a red marker. Of course, you can change the color of the marker to whatever you prefer by passing your choice to the “Color” attribute in your request.
Notice also that we didn’t need to tell the API where are the fields that we want to redact! The API was able to find where these fields are automatically.
Final remarks
The smart redaction endpoint in PassportPDF API is a very powerful utility. You can use it to redact specific fields in a document. You can also choose specific pages from a document you want to redact. Moreover, if your document is in a language other than English, you can specify that using the “Language” field in your request. You can find more details about this endpoint in the documentation.