
PassportPDF getting started guide with Python
Introduction
PassportPDF API is a REST API that lets you perform complex operations on documents and images easily. You may consume the API by using our SDK, or any REST client by sending your requests to the appropriate endpoints. Here’s a list of all the available endpoints :
- Config
- DocumentAI
- Document
- DocuVieware
- Image
- PassportManager
- PassportPDFApplicationManager
More details about these endpoints can be found on the API reference page
Creating an account on PassportPDF
To use PassportPDF API endpoints, you first need to create an account here. Once you do that, you can choose a plan for using the API. Each plan that we have gives you a specific number of “tokens”. Tokens are units that we use to measure how much processing each request needs. Whenever you make a request to the API, you are running an operation on our servers. Some operations require more tokens because they consume more resources.
Using PassportPDF API endpoints with Python
To use the API endpoints above with Python, you will need to have :
- Python installed on your machine.
- requests Python package installed.
- Xlsxwriter Python package installed.
- An account on PassportPDF with a valid number of tokens. You can always check the number of tokens you have left by logging to your account on PassportPDF.
To make calls to any endpoint, you should use the URL in the form of :
https://passportpdfapi.com/api/endpoint_name
So for example, if you would like to use the endpoint DocumentAI, you would make your API calls to the following URL:
https://passportpdfapi.com/api/documentai
For every call you make, you need to use the “passport code” that was given to you when you chose a plan in your account on PassportPDF. This passport code needs to be part of the headers of your API call.
Full Python example
In this tutorial we will see how to extract key information from invoices (invoice number, phone number, total amount, …) and then how to save them to an Excel sheet. All of this will be done automatically through Python.
We will be sending POST requests to DocumentAI endpoint to extract relevant information that could be found in invoices.
import requests import xlsxwriter if __name__=="__main__": endpoint = "https://passportpdfapi.com/api/documentai/AnalyzeDocument" data = { "URI":"https://passportpdfapi.com/test/invoice.png" } headers = { "X-PassportPDF-API-Key" : "YOUR-PASSPORT-CODE", } response = requests.post(endpoint, json=data, headers=headers) path_to_save_json = "data/output/response.json" if(response.status_code == 200): json_response = response.json() pages = json_response["Pages"] page1 = pages[0] key_value_pairs = page1["KeyValuePairs"] # Create workbook workbook = xlsxwriter.Workbook("data/output/invoice_info.xlsx") # Create Excel sheet worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") worksheet.write(0, 2, "Value Type") for i, kvp in enumerate(key_value_pairs): i = i + 1 key = kvp["Key"]["Content"] val = kvp["Value"]["Content"] data_type = kvp["Value"]["DataType"] worksheet.write(i, 0, key) worksheet.write(i, 1, val) worksheet.write(i, 2, data_type) workbook.close() else: print("Something went wrong!")
If the call is successful, you will have a response similar to the image below :
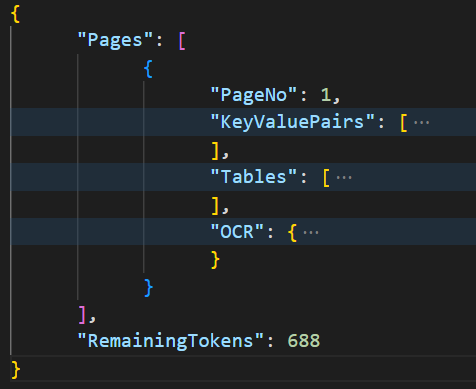
As you can see, the response contains a lot of information that’s structured pagewise. In each page, you will have :
- The page number.
- Key information as a key-value pair structure.
- Tables that exist in the document with the corresponding rows and columns.
- OCR results that are structured in the form of paragraphs, lines and words.
In the code above, once we validate the response, we generate a new Excel file and then we take the extracted information in the KeyValuePairs field and we put it inside this Excel sheet :
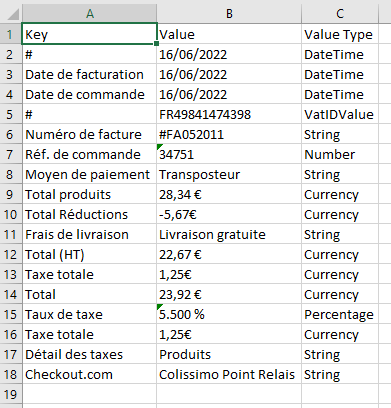
This output is what we call “key value pairs”. In form-like documents such as invoices, it is often needed to extract key information by associating two entities. For example in the invoice we’re using, there is a field called “Total” which is associated with “23,92€”. Here, the key is “Total” and the value is “23,92€”.
Using the code above, we extracted : the key, the value and the value type
You can easily imagine how powerful this PassportPDF utility can be. You can process large amounts of invoices and then take the relevant information from them and put them in an excel sheet for later use or analysis.
More on the Key-Value pair engine in PassportPDF
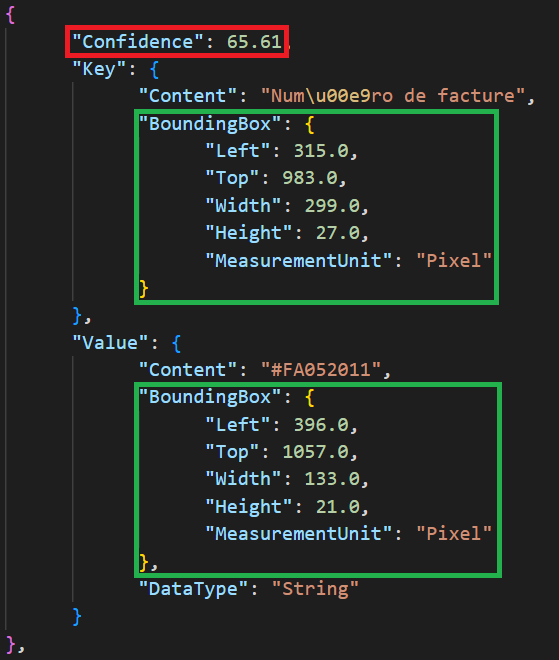
The key-value pair engine gives you a lot of flexibility when working with form-like documents. For example, you can filter the results of this engine based on a confidence level. For each pair in the key-value pairs that were extracted, there is a field called “Confidence” which you can use to threshold information. This field is highlighted in red in the figure below.
Also, for each key and value, you will get their coordinates, which will allow you to know exactly where they are on the invoice. They are highlighted in green in the figure below.
Final remarks
At the end of the response, you can notice that it shows you the number of remaining tokens you have. This number will be identical to the number on your PassportPDF account.