
Parsing PDF documents using Python
Introduction
In this tutorial, we will look at how to parse a PDF document and extract text from it using PassportPDF API and Python. You should have your machine already set up using instructions from the getting started guide.
Why would you need to parse a PDF document?
Parsing a PDF document is very important for enabling automation and streamlining processes. In most businesses, there is a need to process large amounts of documents. PDF is one of the leading formats for document representation, so there is a business need for parsing PDF documents.
Once a PDF document has been parsed, its data is extracted and used in different ways. For example, once the text contained in the document is extracted, we can analyze it and make decisions based on its content.
Parsing PDF documents using PassportPDF API and Python
PassportPDF API enables the parsing of PDF documents. In this tutorial, we’re going to OCR a PDF document and then extract the text from it.
It’s important to know that there are 2 different types of PDF documents:
- Text-based PDF documents.
- Image-based PDF documents.
For text-based PDF documents, there is already an OCR layer that allows you to extract text.
Image-based PDF documents, such as scanned PDFs, for example, do not have an OCR layer. To parse such a document and extract text, you first need to generate an OCR layer.
In the example below, we’re going to look at the second type of PDF document, which is image-based. This will show you how easy and powerful the PassportPDF API is.
In this tutorial, we are going to use the following endpoints:
- DocumentLoadFromURI to load a document from a URI.
- OCR to generate an OCR layer on the PDF document.
- ExtractText to extract the text from the PDF document.
- DocumentClose to close the document.
The use of these endpoints is shown in the code below:
import requests if __name__=="__main__": endpoint = "https://passportpdfapi.com/api/document/DocumentLoadFromURI" headers = { "X-PassportPDF-API-Key" : "YOUR-PASSPORT-CODE", } data = { "URI" : "https://passportpdfapi.com/test/invoice_with_barcode.pdf" } response = requests.post(endpoint, json=data, headers=headers) if(response.status_code == 200): json_response = response.json() file_id = json_response["FileId"] data = { "FileId" : file_id, "PageRange" : "*", } # OCR the document ocr_endpoint = "https://passportpdfapi.com/api/pdf/OCR" ocr_response = requests.post(ocr_endpoint, json=data, headers=headers) if(ocr_response.status_code == 200): json_response = ocr_response.json() # Extract text from the document extract_text_endpoint = "https://passportpdfapi.com/api/pdf/ExtractText" extract_text_response = requests.post(extract_text_endpoint, json=data, headers=headers) if(extract_text_response.status_code == 200): json_response = extract_text_response.json() else: print("Something went wrong when trying to extract text from the document!") # Close document close_document_endpoint = "https://passportpdfapi.com/api/document/DocumentClose" close_response = requests.post(close_document_endpoint, json={"FileId" : file_id}, headers=headers) if(close_response.status_code == 200): print("Document closed successfully.") else: print("Could not close document!") else: print("Something went wrong!")
The PDF document we used in this tutorial is shown below:
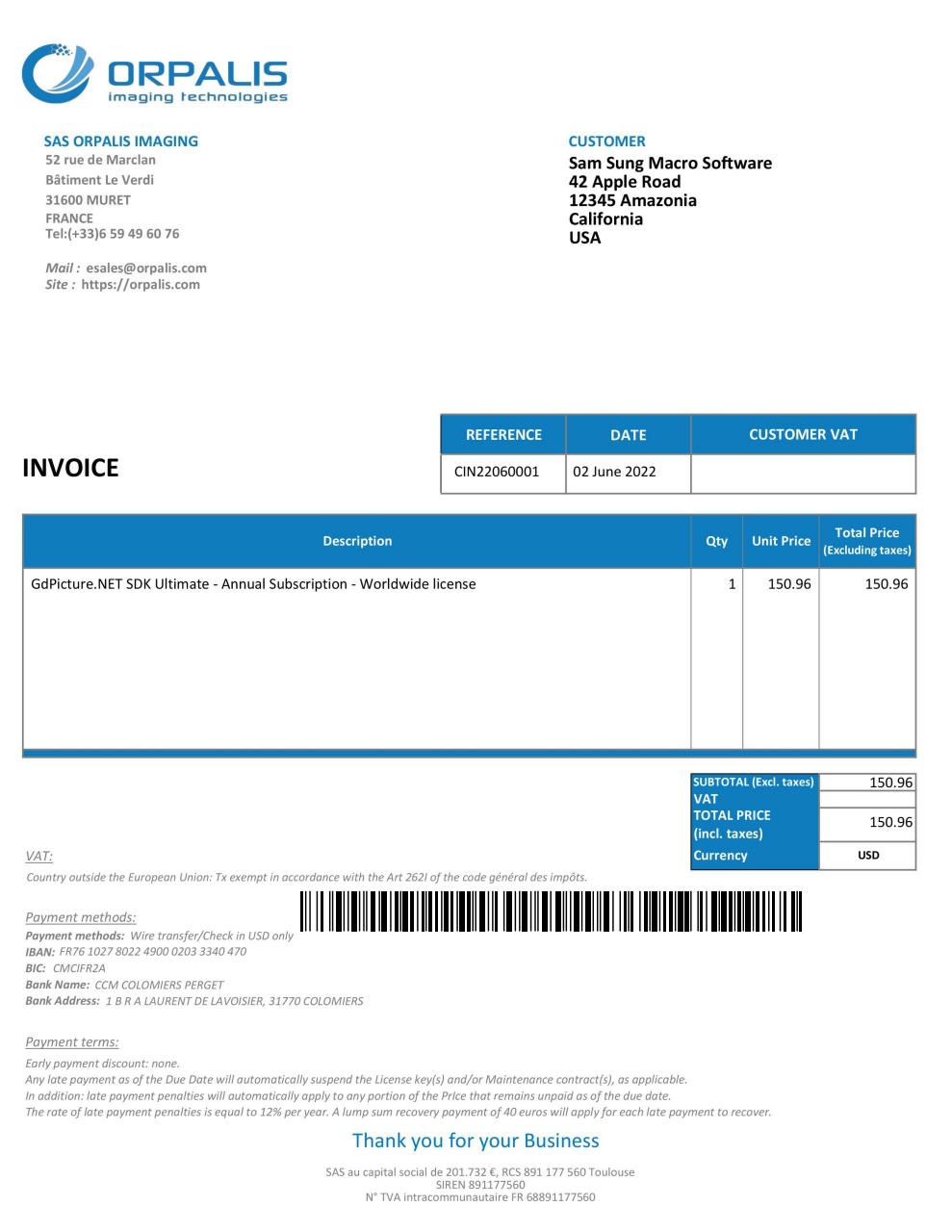
The JSON response representing the extracted text will be a dictionary of 2 entries: ExtractedText and RemainingTokens.
The ExtractedText entry will contain a list of elements.
Each element represents a page in the PDF document. So each element of this list will be a dictionary of 2 entries: ExtractedText and PageNumber. The figure below shows a snippet of the output (the full response has been intentionally truncated for visualization purposes).

Final remarks
If you don’t run the OCR endpoint first before you try to extract the text, you will be getting an empty list for the extracted text. It is because, as mentioned above, image-based PDF documents need an OCR layer before you can extract any text.
For more information about the endpoints used in this tutorial, visit the PassportPDF REST API Reference.