
Parsing PDF documents using .NET and C#
Introduction
In this tutorial, you will learn how to parse PDF documents and extract text from them using the .NET framework and PassportPDF API. Please check our getting started guide for setting up your machine.
There is a business need for parsing PDF documents
Since PDF is one of the most widely used document formats in the world, many businesses use it to store information. Most of these businesses process large amounts of PDF documents daily. So to consume this information, businesses need to parse these documents and extract text from them.
Parsing PDF documents can help in automating and streamlining processes because once a document is parsed, the text contained in that document can be analyzed and decisions can be made based on the content of that text.
How to use PassportPDF API and .NET to parse a PDF file
In this tutorial we will be using PassportPDF API to OCR a document and then extract text from it.
It’s important to know that there are 2 different types of PDF documents:
- Text-based PDF documents.
- Image-based PDF documents.
For text-based PDF documents, there is already an OCR layer. This layer makes the process of extracting text from the document straightforward.
On the contrary, image-based PDF documents such as scanned PDFs do not have an OCR layer. This means that to parse such a document and extract text from it, you first need to generate such a layer.
In the example below, we will look at image-based PDF documents. This will show you how easy and powerful the PassportPDF API is.
We will use these endpoints:
- DocumentLoadFromURI to load a document from a URI.
- OCR to generate an OCR layer on the PDF document.
- ExtractText to extract the text from the PDF document.
- DocumentClose to close the document.
The code below illustrates how to use these endpoints:
using PassportPDF.Api; using PassportPDF.Client; using PassportPDF.Model; namespace TextExtraction { public class TextExtractor { static async Task Main(string[] args) { GlobalConfiguration.ApiKey = "YOUR-PASSPORT-CODE"; PassportManagerApi apiManager = new(); PassportPDFPassport passportData = await apiManager.PassportManagerGetPassportInfoAsync(GlobalConfiguration.ApiKey); if (passportData == null) { throw new ApiException("The Passport number given is invalid, please set a valid passport number and try again."); } else if (passportData.IsActive is false) { throw new ApiException("The Passport number given not active, please go to your PassportPDF dashboard and active your plan."); } string uri = "https://passportpdfapi.com/test/invoice_with_barcode.pdf"; DocumentApi api = new(); Console.WriteLine("Loading document into PassportPDF..."); DocumentLoadResponse document = await api.DocumentLoadFromURIAsync(new LoadDocumentFromURIParameters(uri)); Console.WriteLine("Document loaded."); PDFApi pdfApi = new(); Console.WriteLine("Launching text recognition process..."); PdfOCRResponse ocrPdfResponse = await pdfApi.OCRAsync(new PdfOCRParameters(document.FileId, "*") { Language = "eng", SkipPageWithText = false }); if (ocrPdfResponse.Error is not null) { throw new ApiException(ocrPdfResponse.Error.ExtResultMessage); } else { Console.WriteLine("Text recognition process ended."); } Console.WriteLine("Start text extraction process..."); PdfExtractTextResponse extractTextResponse = await pdfApi.ExtractTextAsync(new PdfExtractTextParameters(document.FileId, "*") { TextExtractionMode = PdfExtractTextMode.WholePagePreserveLayout }); Console.WriteLine("Text extracted :"); foreach (PageText page in extractTextResponse.ExtractedText) { Console.WriteLine($"======== Page {page.PageNumber} ========"); Console.WriteLine(page.ExtractedText); Console.WriteLine("========================"); } } } }
For the full .NET project, please visit the GitHub repository.
The PDF document we used in this tutorial is shown below:
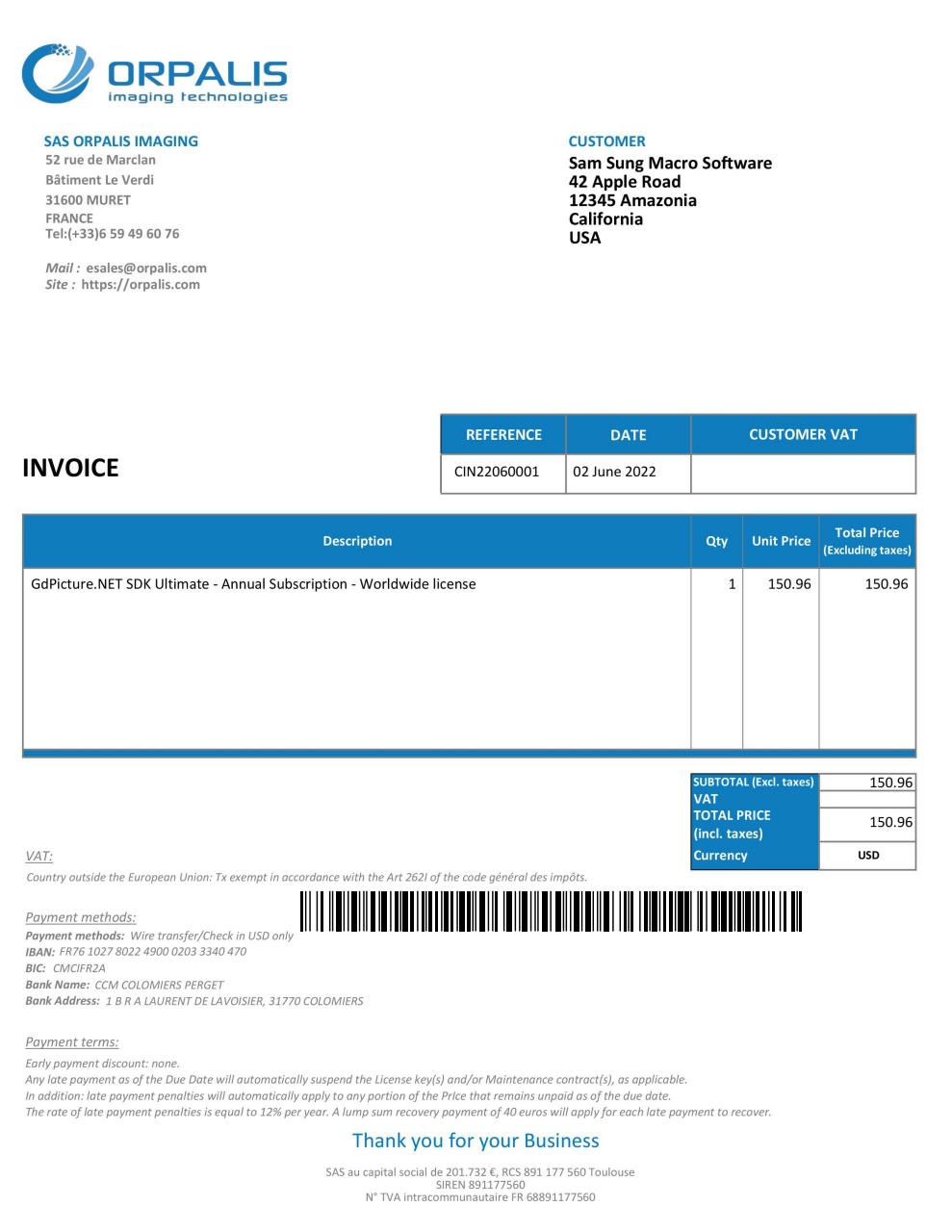
The ExtractedText entry contains a list of elements.
Each element represents a page in the PDF document. For each page, there are 2 entries: ExtractedText and PageNumber. Below you can see the full response:
Final remarks
If you don’t run the OCR endpoint first before you try to extract the text, you will be getting an empty list for the extracted text. This is because, as mentioned above, image-based PDF documents need an OCR layer before you can extract any text.
For more information about the endpoints used in this tutorial, please visit the PassportPDF API reference.